
数据的归一化
数据的归一化是将数组的数据全部映射到一个特定区间进行处理,在数据分析中,一般是将数组的全部数据映射到区间[0,1]。
例1 鸢尾属植物数据集的归一化
鸢尾属植物数据集包括了三类不同的鸢尾属植物,分别是Iris Setosa、Iris Versicolour和Iris Virginica,每类收集了50个样本,每个样本描述了花萼长度、花萼宽度、花瓣长度、花瓣宽度,单位是厘米,该数据集共有150个样本。
数据集以文本格式存储,每行1个样本,共150行,每行有5列,前4列描述了样本的4个特征,第5列是鸢尾属植物名称。
例如下面的数据行:
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
…………
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica从给出的数据集可以看出,特征数据的数值范围基本不在区间[0,1]内,若要对该数据集进行数据分析,需要对特征数据进行归一化处理。下面将数据集的第1列做归一化处理。
# 导入numpy库
import numpy as np
# 程序入口
if __name__ == '__main__':
# 从数据集文件读取第1列特征数据
data = np.genfromtxt('iris.data',delimiter=',',dtype='float', usecols=[0])
# 获取数据集的最大值和最小值
max, min = data.max(), data.min()
# max - min作为基数对数据归一化处理
result = (data - min)/(max - min)
print(result)代码解读
numpy库的genfromtxt()函数从文本文件读取数据集,第1个参数为文本文件的路径,支持本地和网络文件;第2个参数为为列数据字段间的分隔符;第3个参数为读入的数据类型;第4个参数设置读取的列数据。
max和min为读取数据集的最大值和最小值,并通过max-min作为基数进行数据的归一化处理。
计算数据的相关系数
相关系数是研究两个变量之间线性相关程度的量,对于鸢尾属植物数据集来说,相关系数反映了每两列数据之间的线性相关程度。例如:花萼长度和花瓣长度的相关性、花萼宽度和花瓣宽度的相关性等。
相关系数一般在-1~1之间,该值为正数时为正相关,为负数时为负相关,为0时没有相关性。该值越接近于1,说明两个变量之间正线性相关越强,该值越接近于-1,说明负线性相关越强。
因变量值随自变量值的增大(减小)而减小(增大),在这种情况下,因变量和自变量的相关系数为负值,即负相关。
例2 计算鸢尾属植物数据集花萼长度和花瓣长度的相关系数
# 导入numpy库
import numpy as np
# 程序入口
if __name__ == '__main__':
# 从数据集文件读取第1列和第3特征数据
data = np.genfromtxt('iris.data',delimiter=',',dtype='float', usecols=[0,2])
# 提取第1列数据
col1 = data[::,0]
# 提取第3列数据
col2 = data[::,1]
# 计算两列数据的相关系数
r = np.corrcoef(col1,col2)
print(r)代码解读
numpy库的corrcoef函数计算两列数据的相关系数,输出结果是两列数据的相关系数矩阵:
[[1. 0.87175416]
[0.87175416 1. ]]相关系数为1的是列自身的相关系数,花萼长度和花瓣长度的相关系数为0.87175416。
数据分类统计
有时对数据进行分类统计是非常有用的,分类统计可以反映总体内部各部分之间的差别和相互关系。例如:对鸢尾属植物数据集的花萼按长度区间进行分类。
例3 对鸢尾属植物数据集的花萼数据按长度区间分类
花萼长度区间范围:small(<3),medium(3~5),large(>5)
# 导入numpy库
import numpy as np
# 程序入口
if __name__ == '__main__':
# 读取数据集
data = np.genfromtxt('iris.data',delimiter=',',dtype='float')
# 提取数据集第3列数据
third_data = data[:,2]
# 定义存储分类数据的列表
samll,medium,large = [],[],[]
# 定义分类区间
bins = [0, 3, 5, 10]
# 调用numpy库的digitize函数对数据分类
petal_length = np.digitize(third_data.astype('float'), bins)
for n in range(third_data.size):
if bins[petal_length[n]-1] >= 0 and bins[petal_length[n]] <= 3:
samll.append(third_data[n])
if bins[petal_length[n]-1] >= 3 and bins[petal_length[n]] <= 5:
medium.append(third_data[n])
if bins[petal_length[n]-1] >= 5 and bins[petal_length[n]] <= 10:
large.append(third_data[n])
print(samll)
print(medium)
print(large)代码解读
Numpy模块的digitize()函数对数值数据按照给定的数值范围分类,函数的第1个参数是待分类的数组,第2个参数是分类区间数组。函数返回分类数组每个元素所属的分类区间数组的区间索引。
digitize()函数的定义如下:
digitize(x, bins, right=False)
若bins是单调递增的,那么bins[i-1]<=x<bins[i];如果bins是单调递减的,那么bins[i-1]>x>=bins[i]。若x中的值超出了bins的界限,则会根据需要返回0或len(bins)。如果right为True,则bins右边是闭区间,索引i使得bin[i-1]<x<=bin[i]或bin[i-1]>=x>bin[i],且bins分别单调递增或递减。
计算向量间的欧式距离
欧式距离也称为欧几里得距离或欧几里得度量,是欧几里得空间中两点间直线距离,多用于数据分析的聚类或相似度计算。
在二维坐标系中,两点间的欧式距离为:
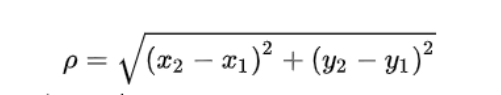
其中(x1,y1)和(x2,y2)是二维坐标系两点的坐标。
在三维坐标系中,两点间的欧式距离为:
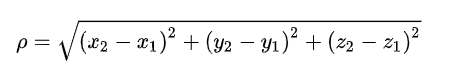
其中(x1,y1,z1)和(x2,y2,z2)是三维坐标系两点的坐标。
在n维坐标系中,两点间的欧式距离为:
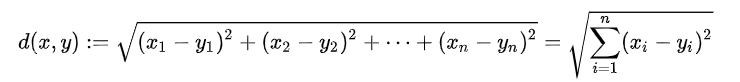
其中(x1,x2,……xn)和(y1,y2,……,yn)是n维坐标系的两点坐标。
n维坐标系的点可以用向量来表示,例如三维坐标系的两点p1和p2可以表示为向量:
p1 = np.array([[3,1,2]])
p2 = np.array([[6,5,7]])例4 计算两个向量间的距离
# 导入numpy库
import numpy as np
# 程序入口
if __name__ == '__main__':
# 三维坐标系p1点
p1 = np.array([[3,1,2]])
# 三维坐标系p2点
p2 = np.array([[6,5,7]])
# 计算两点间L2范数(欧式距离)
dist = np.linalg.norm(p2-p1)
print(dist)代码解读
Numpy库linalg模块的norm()函数计算向量或矩阵的范数,norm()函数的第1个参数或是向量或是矩阵,第2个参数指定范数类型,默认是L2范数(即欧式距离)。
找出向量的局部极大值
向量的局部极大值是指在向量范围内,两边被较小数值的分量包围的分量。
例如向量:
a = np.array([1, 3, 7, 1, 2, 6, 0, 1])向量a的局部极大值为7和6两个分量,7和6的周围都是小于该值的分量。
例5 找出向量的局部极大值
# 导入numpy库
import numpy as np
# 程序入口
if __name__ == '__main__':
# 定义向量v
v = np.array([1, 3, 7, 1, 2, 6, 0, 1])
# 计算向量v相邻分量的差值
difference = np.diff(v)
# 返回difference分量的正负号
# x>0:1 x=0:0 x<0:-1,x为difference的分量值
difference_sign = np.sign(difference)
# 再次计算difference_sign相邻分量的差值
doublediff = np.diff(difference_sign)
# 返回doublediff分量值为-2的索引向量
peak_locations = np.where(doublediff == -2)
# peak_locations是元组类型,第1个元素是索引向量
# 索引向量做加1操作
# 因为索引向量的分量指向向量v局部极大值分量的相邻分量
peak_locations = peak_locations[0] + 1
print(peak_locations)