初识数据分析:商品间的关联分析
- Python语言
- 2024-07-04
- 861热度
- 0评论
【摘要:课程首先介绍了什么是数据,含有语义的数值才能称为数据。然后通过分析购物篮数据,讲述了数据的关联分析,编写Python程序来实现数据的关联分析,最后简述了要从事数据分析,需要掌握哪些核心技能。】
什么是数据?
在讲数据之前,先说一个关于啤酒和尿布的故事。

这个故事的真假,暂不讨论。说有一个大型超市,每过一段时间,他们会对消费者购买的商品进行分析,找出商品与商品间的关联性。
这里的关联性是指一个消费者购买了一件商品,他会购买另一件商品的概率。例如:一个消费者购买了啤酒,他会购买尿布的概率有多大,是20%还是5%等,这个概率就是商品间的关联性。
举个例子,假如牛奶和面包的关联性是80%,当一个消费者购买了牛奶后,这个消费者会有80%的的概率购买面包。
在“牛奶和面包的关联性是80%”这句话中,“80%”是数值,“牛奶和面包的关联性”是数值的语义,是对数值的解释,数值和数据的语义是不能分隔的。单纯的“80%”对我们来说没有任何意义,它仅是一个百分比。

若上面的数据反映了真实情况,超市的店员就有理由把牛奶和面包的货柜尽量放置的近一些,方便购买牛奶的消费者能很快买到面包,对另外20%的消费者也起到促销面包的作用。
理解了商品间的关联性,再回到前面大型超市的故事,这个大型超市对用户购买商品的数据进行分析后,得出了这样一条结论:

为什么会得出这样的结论呢?数据是真实的数据,数据不会说谎。经过跟踪调查发现,一些年轻的爸爸常到超市去购买婴儿尿布,有30%至40%的新爸爸,会顺便买点啤酒犒劳自己。根据得出的数据,这个超市对啤酒和尿布进行了捆绑销售,不出意料,销售量双双增加。
超市若需要对商品间的关联性进行分析,需要获取大量用户购买商品的数据,作为分析的基础。
在超市购物结账后,超市的结账员会给消费者一个小票,这个小票记录了购买的商品和价格信息,主要包括商品名称、商品单价、商品数量、商品金额、购买日期、所有商品的总金额。
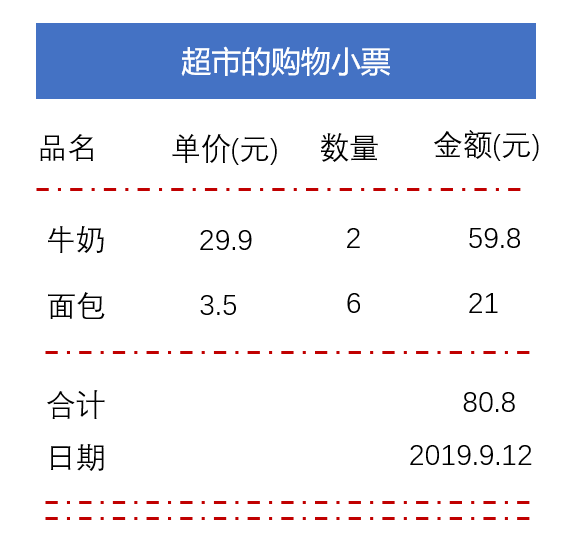
假设一个消费者从超市购买1箱牛奶和6个面包并结账后,超市可以从该消费者获取下表所列的商品数据:
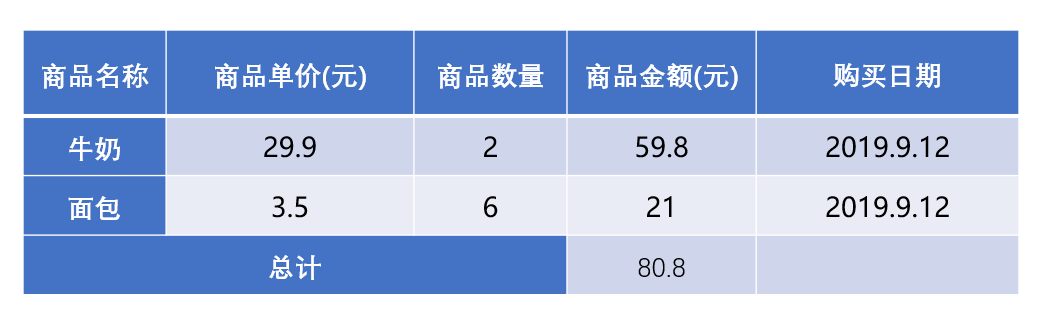
在上面的表格中,数值29.9、59.8、3.5、1、6、21、80.8,若离开了表格对这些数值的描述,我们将不清楚这些数值的作用是什么,以及这些数值表示的含义。它们就是一些纯的数值,没有任何意义,因此这些数值如果没有语义解释,只能称为数值,不能称为数据。

通过使用表格结构以及文字对数值的描述,我们获取了这些数值带给我们的信息。也可以这样说,带给我们信息的、能够让我们理解的数值、文字、图像、视频、符号等内容就是数据。
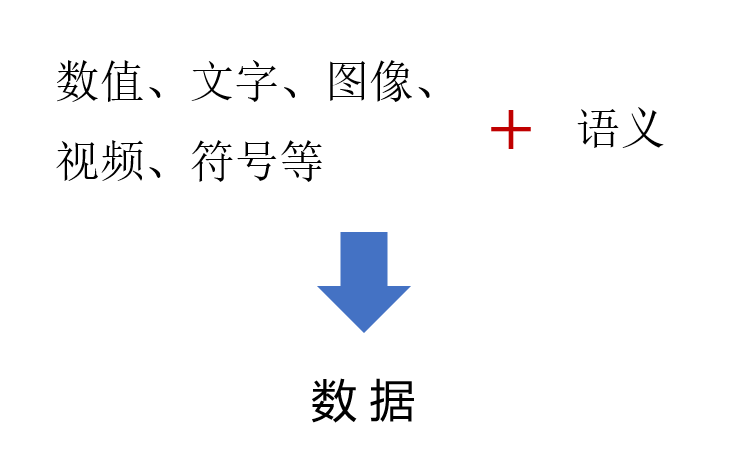
在一些约定情况下,数值不需要特定的描述信息,也能让人们理解数值的含义。
例如:可以约定下面的一组数值用于表示A超市今年前6个月的营业额,数值按1至6月份排列,单位为万元:

上面的一列数值在约定数值语义的情况下,我们可以理解这些数值的含义:

在编写程序处理数值时,也会约定要处理数值的语义。例如在计算长方形面积的程序中,会声明两个变量width和height,这两个变量存储了用户输入的长方形的宽度和高度两个数值。在程序中,我们通过变量和数值的关系约定了用户输入的宽度和高度两个数值的语义。

商品间的关联分析
商品间的关联分析主要通过关联规则进行,关联规则主要依据定制的规则来判断两个或多个事物间的关联程度。
关联规则的经典应用就是购物篮的数据分析,目的是找出顾客在商场所选购商品之间的关联程度,下面是一个关联规则的例子:
牛奶 → 面包 [支持度= 30%,置信度 = 80%]
这个规则表明有30%的顾客同时购买了牛奶和面包,在购买牛奶的顾客中有80%也购买了面包。规则中的支持度和置信度是进行关联分析的两个重要指标。
在商品间关联分析中,支持度是指顾客同时购买A商品和B商品的概率,置信度是顾客在购买A商品的前提下,同时购买B商品的可预测度。
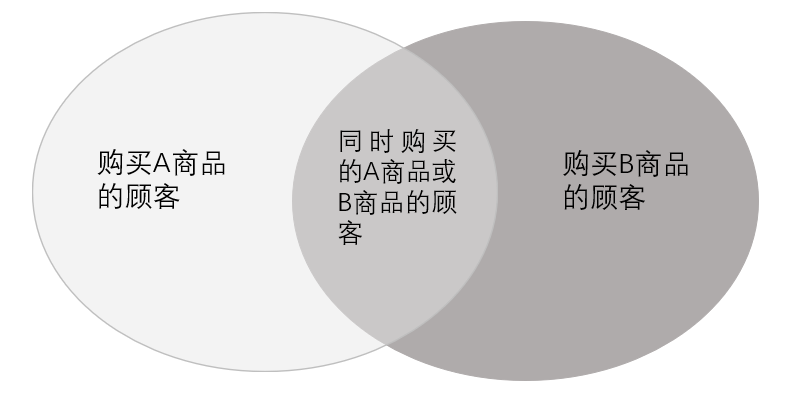
上图两个椭圆的交集就是同时购买A商品或B商品的顾客。
商品间的关联规则可以这样来描述:设A={A(1),A(2),……,A(m)}是商品集合(也称为项目集合),T={t(1), t(2),……,t(n)}是商品不同组合的集合(也称为事物集合),其中每个t是顾客购买的一次商品组合记录,并满足t(1)包含于A。
一个关联规则是如下形式的蕴涵关系:
X —> Y ,其中 X 包含于A,Y包含于A,并且X与Y的交集为空。
例如:
某商店的全部商品为A,一位顾客购买的商品集合称为一个事务t,T为全部事务集合,一个事务可以是:
{牛奶,面包,衣服}
该事务的一条关联规则是:
牛奶,面包 —> 衣服
其中{牛奶,面包}是X,{衣服}是Y,在表示事务和规则时,两边的大括号可以忽略不写。
在明确了规则和事务的基础上,下面给出支持度和置信度的计算公式。
支持度 = (XUY).count/T.count
其中(XUY).count表示X与Y取并集后在在全部事务中出现的次数,T.count表示全部事务的次数。
支持度评价了X事和Y事务的依赖程度,若该值过小,说明X事务和Y事务的依赖程度低,不建议X事务内的商品与Y事务内的商品捆绑销售。
置信度是X事务和Y事务在T事务集合中出现次数,与X事务在T事务集合中出现次数的百分比。
置信度 = (XUY).count/X.count
其中(XUY).count表示X与Y取并集后在在全部事务中出现的次数,X.count表示X事务在T出现的次数。
置信度评价了顾客在购买X事务的前提下,同时购买Y事务的可预测度,若该值过小,同样不建议X事务内的商品和Y事务内的商品捆绑销售。
例1 下面是一个简化的商品购买数据集合T,每条数据t(i)表示一位顾客在超市一次购买商品的组合。
购买数据集合T:
t(1):牛奶、面包、牛肉
t(2):牛奶、猪肉
t(3):猪肉、火腿
t(4):牛奶、面包、火腿
t(5):牛奶、面包、衣服、火腿、牛肉
t(6):面包、衣服、牛奶
t(7):面包、牛奶、衣服
现在需要对上面的商品数据进行关联分析,找出所有符合条件的关联规则,对商品进行捆绑销售。
为此需要计算关联规则的支持度和置信度,两者的值越高,说明商品间的关联程度越高,可以对商品进行捆绑销售。分别对支持度和置信度设置一个阈值,高于该阈值的关联规则被采纳,低于该阈值的关联规则被丢弃。
若支持度阈值=30%,置信度阈值=80%,则下面这条关联规则是符合要求的:
衣服 → 牛奶、面包 [支持度= 3/7,置信度 = 3/3]
支持度的计算过程如下:购买数据集合T共有7条购买记录,同时购买衣服、牛奶和面包的记录数为3,因此支持度为3/7,高于设定的支持度阈值。
置信度的计算过程如下:同时购买衣服、牛奶和面包的记录数为3,购买衣服的记录数为3,因此置信度为3/3,高于设定的置信度阈值。
下面的规则也是符合要求的:
衣服、面包 → 牛奶 [支持度= 3/7,置信度 = 3/3]
从以上的数据中,还可以找出更多符合要求的规则,下面使用Python程序来找出符合要求的所有规则。
使用Python程序进行关联分析
编写Python程序,实现对案例1关联规则的提取。
from itertools import combinations
# 定义频繁集类,频繁集为支持度大于阈值的商品组合
class FrequentlyItem:
# 频繁集
items = []
# 频繁集在购物篮数据中出现的次数
count = 0
# 频繁集支持度
support = 0
def __init__(self,items,support,count):
self.items = items
self.support = support
self.count = count
# 定义购物篮数据
shop_cart = [
["牛奶","面包","牛肉"],
["牛奶","猪肉"],
["猪肉","火腿"],
["牛奶","面包","火腿"],
["牛奶","面包","衣服","火腿","牛肉"],
["面包","衣服","牛奶"],
["面包","牛奶","衣服"]
]
# 定义频繁集列表
frequently = []
# 定义商品集合
goods = set()
# 定义支持度阈值
minsupport = 0.3
# 定义置信度阈值
minconfidence = 0.8
# 定义商品汇总函数
def summary_goods():
# 遍历shop_cart
for items in shop_cart:
for item in items:
goods.add(item)
# 定义查找频繁集函数
def find_frequently():
# 集合对象转换为列表对象
goods_list = list(goods)
# 若列表对象为空,则返回
if len(goods_list) == 0:
return
# 生成两个或以上商品的所有组合
for count in range(2,len(goods_list)):
# 使用combinations函数生成组合
frequently_list = combinations(goods_list,count)
# 验证每组商品是否满足频繁集要求
for item in frequently_list:
calculation_support(item)
# 计算支持度
def calculation_support(frequently_list):
count = 0
for item in shop_cart:
# 使用集合运算
ret = set(frequently_list) <= set(item)
if ret:
count += 1
# 计算该组合商品的支持度
support = count / len(shop_cart)
if support >= minsupport:
# 添加到频繁集列表
item = FrequentlyItem(frequently_list,support,count)
frequently.append(item)
# 计算sub_list在shop_cart出现的记录数
def calculation_count(sub_list):
count = 0
for item in shop_cart:
# 使用集合运算
ret = set(sub_list) <= set(item)
if ret:
count += 1
return count
# 程序入口
if __name__ == '__main__':
# 汇总商品
summary_goods()
# 找出频繁集
find_frequently()
# 输出关联规则
for item in frequently:
# 从频繁集中生成组合
for count in range(1,len(item.items)):
temp_list = combinations(item.items,count)
# 计算置信度
# subitem_A为item.items的子集
# subitem_B为item.items的另外一个子集
# subitem_A和subitem_B的并集为item.items
# 计算subitem_A推出subitem_B的置信度
for subitem_A in temp_list:
# 求subitem_B
subitem_B = set(item.items).difference(set(subitem_A))
# 计算subitem_A在shop_cart列表中出现的记录数
count_a = calculation_count(subitem_A)
# 计算subitem_A推出subitem_B的置信度
confidence = item.count / count_a
if confidence >= minconfidence:
print("{%s} -> {%s}" % (str(subitem_A),str(subitem_B)))
编程思路:
定义一个FrequentlyItem频繁集类,用于存储大于设定的商品组合,所有的关联规则将从频繁集产生。
函数find_frequently()用于产生频繁集列表,生成方法是通过combinations()函数创建goods商品集合的所有组合(组合数分别为2件商品至商品集合总量),计算该组合在shop_cart的支持度,若支持度大于minsupport,则创建频繁集,并添加到frequently频繁集列表。
遍历frequently频繁集列表,对每一个频繁集类通过combinations()函数产生不同数量的商品组合,构成事务subitem_A和subitem_B,计算subitem_Asubitem_A推出subitem_B的置信度,若置信度大于minconfidence,则输出该规则。
从事数据分析需要的核心技能
数据分析主要涉及到三部分工作:数据预处理、分析研究和结果表达。作为一个数据分析工程师,数据预处理、分析研究和结果表达是必须要掌握的核心技能。
数据预处理技能
数据预处理主要是数据的收集和清洗。可以使用多种技术来收集数据,爬虫可以在较短时间内从互联网收集大量的数据,也可以通过编写程序来定向采集数据,也可以通过访问调查、邮寄调查、电话调查、座谈会、个别深度访问、网上调查等方法来采集数据。
一般来说数据在收集过程中,会对数据进行过滤和清洗,将数据按照定制的分析规则存储到数据库中。例如:商店的顾客购买数据来自商店的结算终端,每个结算终端都会连接到一个中心数据库,将顾客的购买数据按数据库表结构进行组织,并存储到数据库内。
数据预处理涉及到的技术或工具有:爬虫技术、数据库技术、SQL查询技术、以及各类数据采集和处理工具。
数据分析研究技能
EXECL 是最基本、最常见的数据分析工具了,人们通常使用EXECL来完成基本的数据分析,并使用各种图表来展现分析结果。EXECL主要针对小数据量且分析较为简单的情况,当分析的数据量较大,且分析过程比较复杂时,EXECL就很难胜任数据分析工作了。
例如:大型商店一天可能会产生上万条购买记录,一个月就会产生几十万条记录,要从这几十万条购买记录中找出商品的关联规则,就需要更强大的分析工具,编写高效的分析算法来支撑对大数据的分析。
课程案例中的分析算法效率比较低下,多次遍历商品集合并重复构成不同的商品组合,当数据量过大时,会导致程序运行缓慢、甚至发生崩溃。商品关联分析比较有效的算法是Apriori算法,Apriori算法基于演绎原理来高效地产生频繁项目集。关于Apriori算法,在后面的课程会详细讲述。
使用Python编写数据分析程序时,Pandas是一个非常好用的数据分析工具,它利用科学计算工具Numpy对数据进行分析计算,它纳入了大量数据分析库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
结果表达技能
数据分析结果一般都是通过各种图表展现出来,便于使用者快速理解。在Python中,绘制各类图表的工具是Matplotlib,使用Matplotlib可以绘制各类统计图表。