贪心算法思想
- 算法
- 2024-06-22
- 1058热度
- 0评论
基本概念
现在假设有面值1角、2角、5角、10角(1元)的硬币各10枚,要求用最少的硬币数量来找零。
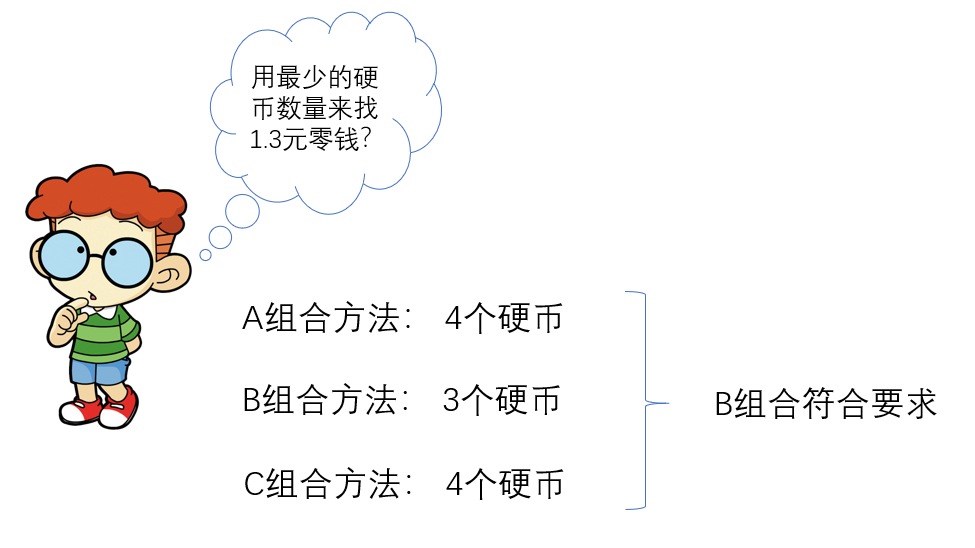
例如:找1.3元的零钱,1.3元转换成角,就是13角。

找零钱就是把不同面值或同一面值的硬币组合起来,组合的面值等于需要找零的钱数。1.3元就是13角。
下面有A、B、C三种硬币的组合方法:
A组合方法:1个10角的硬币、3个1角的硬币;
B组合方法:1个10角的硬币、1个2角的硬币、1个1角的1币;
C组合方法:2个5角硬币、1个2角硬币、1个1角硬币。

在上面的三种硬币面值组合中,A组合需要4个硬币、B组合需要3个硬币、C组合需要4个硬币。
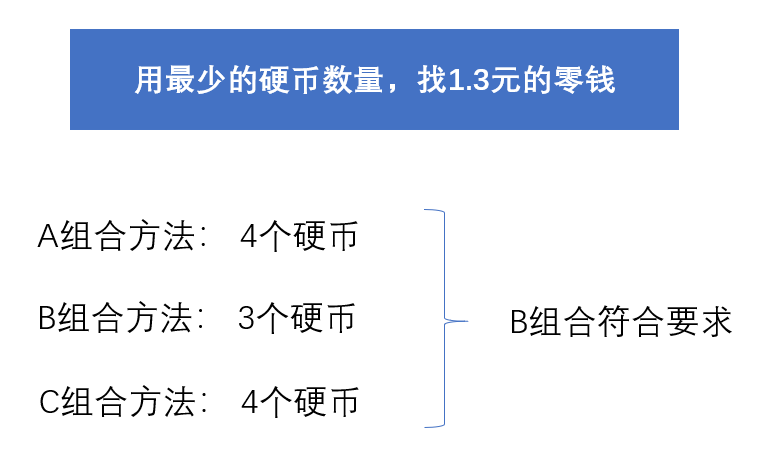
显然,B组合是最优组合,也称为问题的最优解。因为A、B、C三种组合都是问题的解,但只有B组合符合人们对问题解的要求。
感兴趣的同学有时间时可以进行更多种的组合,看看还有没有最优解。
在前面的找零问题中,A、B、C三种硬币组合都是问题的解,都可以组合成1.3元的零钱,但符合人们要求的解只有B组合,B组合也称为问题的最优解。
问题的最优解可以简单理解为符合人们预期或让人满意的问题解法。例如在找零问题中,人们的预期是用最少的硬币数找零,在A、B、C三种找零的解法中,B是符合预期的,因此B是最优解,A和C就不是最优解。
在同一问题的解法中,有时最优解可能不止一个。例如外出旅行时,希望旅行预算在5000以内,因此5000以内的预算方案都是最优解,在这里我们就不再讨论了。

问题的最优解是与人们预期相关的,人们对问题最满意的解法就是问题的最优解。举个容易理解的例子:在算数问题中,假设以算的快为人们满意的解法。那么,当求解从1开始一直加到10这个问题时,(1+10)*5的解法就是最优解,它显然要比1+2+3+4+5+6+7+9+10这么计算要快的多。
在A、B、C三种找零算法中,B找零算法是首先选择面值最大的硬币,然后再选择面值次之的硬币,依次类推直至硬币组合的面值等于零钱数。这种算法也称为贪心算法(也叫贪婪算法),贪心算法就是在解决问题的过程中,总是做出在当前看来是最好的选择。
贪心算法并不保证总是得到全局最优解,因为它只考虑当前状态下的最优选择,而不考虑全局最优解的可能性。
零钱兑换问题
问题描述
假设你手上有面值为1、5、10、25的硬币,给定一个总金额,如何用最少数量的硬币凑齐这个金额?贪心算法的策略是每次都选择当前面值最大的硬币,直到凑齐所需金额。
解题步骤
初始化变量:
设定一个整数变量amount来存储目标总金额。
设定一个整数数组coins来存储可用的硬币面值。
设定一个整数变量count来记录已经使用的硬币数量,初始值为0。
设定一个整数变量remaining来记录剩余的金额,初始值为amount。
对硬币面值进行排序:
使用排序算法(如冒泡排序、快速排序等)对coins数组进行从大到小的排序,以确保优先使用面值较大的硬币。
循环直到金额凑齐:
使用一个循环,直到remaining变为0为止。
在循环内部,遍历排序后的coins数组。
对于每个硬币面值,计算当前面值能使用的最大数量,即remaining除以当前面值的整数部分。
将计算出的数量加到count上,并从remaining中减去相应金额。
处理无法凑齐金额的情况:
如果在循环结束时remaining不为0,表示无法使用给定的硬币面值凑齐目标金额,返回-1或其他错误标识。
返回结果:
如果成功凑齐金额,返回count作为结果,即所需的最少硬币数量。
代码实现
#include <stdio.h>
// 冒泡排序函数,用于对硬币面值进行排序
void bubbleSort(int coins[], int n) {
int i, j, temp;
for (i = 0; i < n - 1; i++) {
for (j = 0; j < n - i - 1; j++) {
if (coins[j] < coins[j + 1]) {
temp = coins[j];
coins[j] = coins[j + 1];
coins[j + 1] = temp;
}
}
}
}
// 贪心算法实现零钱兑换问题
int coinChange(int coins[], int n, int amount) {
int count = 0; // 硬币数量
int remaining = amount; // 剩余金额
// 对硬币面值进行排序
bubbleSort(coins, n);
// 循环直到金额凑齐
while (remaining > 0) {
int i;
for (i = n - 1; i >= 0; i--) { // 从面值最大的硬币开始尝试
if (coins[i] <= remaining) {
int useCount = remaining / coins[i]; // 计算当前面值能使用的最大数量
count += useCount; // 更新硬币数量
remaining -= useCount * coins[i]; // 更新剩余金额
break; // 找到合适的硬币后退出循环
}
}
// 如果没有找到合适的硬币面值,则无法凑齐金额
if (i < 0) {
return -1;
}
}
return count; // 返回所需的最少硬币数量
}
int main() {
int coins[] = {1, 2, 5};
int n = sizeof(coins) / sizeof(coins[0]); // 硬币面值的数量
int amount = 11; // 目标总金额
int minCoins = coinChange(coins, n, amount);
if (minCoins != -1) {
printf("最少需要 %d 枚硬币来凑齐 %d 元\n", minCoins, amount);
} else {
printf("无法凑齐 %d 元\n", amount);
}
return 0;
}
代码首先定义了一个bubbleSort函数来对硬币面值进行排序。然后,coinChange函数使用贪心算法来计算最少需要的硬币数量。最后,在main函数中调用coinChange函数,并输出结果。
算法分析
时间复杂度
代码首先对硬币面值进行排序,这部分的时间复杂度是O(n^2)(使用了冒泡排序)。然后使用while循环,其内部有一个for循环。在最坏情况下,while循环会执行amount/minCoin次(其中minCoin是硬币面值中的最小值),而for循环每次执行n次。因此时间复杂度主要由排序决定,即O(n^2)。
空间复杂度
coinChange函数的空间复杂度是O(1),因为它只使用了几个变量来存储硬币数量、剩余金额等,并没有使用与输入规模n或amount成正比的额外存储空间。coinChange函数内部使用的冒泡排序算法,冒泡排序的空间复杂度是O(1)。
因此,案例代码的空间复杂度是O(1)。
活动选择问题
问题描述
假设有一系列的活动,每个活动都有一个开始时间和一个结束时间,且这些活动在时间上不能重叠。任务目标是选择出最多的互不重叠的活动集合。
解题思路
每个活动都可以用一个区间来表示,例如活动 i 可以表示为区间 [s_i, f_i],其中 s_i 是活动开始的时刻,f_i 是活动结束的时刻。活动的选择需要满足以下条件:对于任意两个被选中的活动 i 和 j,它们的区间不能重叠,即要么 f_i <= s_j,要么 f_j <= s_i。
贪心算法的思路是,首先按照活动的结束时间进行排序,然后尽可能选择结束时间最早且不与已选活动重叠的活动。具体来说,从第一个活动开始考虑,如果它与之前已选的活动没有重叠,则选择它;否则跳过它,继续考虑下一个活动,直到所有活动都被考虑过。
因为按照结束时间排序,因此每次选择结束时间最早的活动可以保证后面还有足够的时间去选择其他活动。同时也避免了活动之间的重叠。
代码实现
#include <stdio.h>
#include <stdlib.h>
// 定义活动结构体
typedef struct {
int start; // 活动开始时间
int finish; // 活动结束时间
} Activity;
// 比较函数,用于qsort排序
int compare(const void *a, const void *b) {
Activity *activityA = (Activity *)a;
Activity *activityB = (Activity *)b;
return (activityA->finish - activityB->finish);
}
// 活动选择问题的贪心算法实现
int greedyActivitySelector(Activity arr[], int n) {
// 首先按照结束时间对活动进行排序
qsort(arr, n, sizeof(Activity), compare);
int count = 1; // 至少有一个活动被选中
int lastFinish = arr[0].finish; // 最后一个被选中活动的结束时间
for (int i = 1; i < n; i++) {
// 如果当前活动的开始时间早于上一个被选中活动的结束时间,则跳过
if (arr[i].start < lastFinish) {
continue;
}
// 否则,选择当前活动
count++;
lastFinish = arr[i].finish;
}
return count;
}
int main() {
// 示例活动数组
Activity activities[] = {
{1, 2},
{2, 3},
{3, 4},
{1, 3},
{4, 5},
{5, 6},
{8, 9},
{7, 10},
{6, 8}
};
int n = sizeof(activities) / sizeof(activities[0]);
// 调用活动选择问题的贪心算法
int maxActivities = greedyActivitySelector(activities, n);
// 输出结果
printf("最多可以选择的活动数量是: %d\n", maxActivities);
return 0;
}
定义Activity结构体来表示活动,它包含活动的开始时间和结束时间。使用qsort函数来对活动数组按照结束时间进行排序。greedyActivitySelector函数是贪心算法的实现,它遍历排序后的活动数组,并选择结束时间最早且不与已选活动重叠的活动。
请注意,上述案例代码假设活动数组是有效的,并且活动的开始时间和结束时间都是合理的。在实际应用中,可能需要添加一些额外的错误检查和边界情况处理。
算法分析
时间复杂度
排序的时间复杂度:qsort函数一般使用快速排序算法,其平均时间复杂度是O(n log n),其中n是活动数组的长度。
贪心选择的时间复杂度:这部分的循环遍历了排序后的数组一次,因此其时间复杂度是O(n)。
由于排序是主要的耗时操作,所以整个算法的时间复杂度是O(n log n)。
空间复杂度
排序的空间复杂度:qsort函数是原地排序(in-place sorting),它不需要额外的存储空间(除了递归调用栈),所以空间复杂度是O(log n)(这里log n是由于递归调用栈的深度,但在平均情况下它通常比n小得多)。
贪心选择的空间复杂度:贪心算法本身没有使用额外的存储空间(除了几个变量),所以其空间复杂度是O(1)。
因此,整个算法的空间复杂度主要由排序决定,是O(log n)。