链表在C语言的实现
- C语言
- 10小时前
- 37热度
- 0评论
本文以图书馆的书目信息表为例,讲解链表在C语言的实现。
定义链表
链表存储的元素称为节点,节点由数据域和至少一个指针域构成,数据域存储数据,指针域存储指向该节点前驱或后驱节点的指针。若节点只有一个指针域,一般指向该节点的后驱节点,若无后驱节点,则该指针域为空或NULL。
C语言实现链表节点
typedef struct Node{
void* data; //数据域
struct Node *pnode; //指针域
}Node;
Node结构有两个成员:data为数据域,类型为void指针,可以指向任何类型的数据;pnode为指针域,指向Node结构。链表节点动态申请,当链表不再使用时,开发者需要删除链表节点,动态申请节点的链表也称为动态链表。
C语言定义图书书目结构
typedef struct{
char strIndex[30]; // 索引号
char name[50]; // 图书名称
char author[15]; // 作者
char press[50]; // 出版社
}BOOKINFO;
BOOKINFO结构共有四个字符数组成员,分别存储图书的索引号、图书名称、作者和出版社。链表节点的数据域为指向BOOKINFO结构的指针。
前面定义了链表节点和图书书目结构,下面实现单链表的HEAD节点(头节点),HEAD节点一般是个空节点,仅是作为链表的一个头节点,节点的数据域可以存储链表内的元素数量。
C语言实现链表HEAD节点
Node *pHead;
pHead = (Node*)malloc(sizeof(Node));
pHead->data = (void*)malloc(sizeof(int));
pHead->data = 0;
pHead->pnode = NULL;
代码使用C语言的malloc()函数从内存申请链HEAD表节点空间,HEAD节点的数据域指向整数类型的数据,用于存储链表内的元素数量,指针域默认为空值。存储链表HEAD节点的变量pHead建议声明为全局变量。
下面来实现单链表的插入运算,并探讨插入算法的复杂度,链表的其它运算请同学们参照插入运算自行给出。
插入运算
在链表插入一个节点,一般是在链表的索引位置插入一个节点。虽然链表存储的节点物理上不连续,但逻辑上是连续的,因此链表的索引位置为链表内节点的序号。例如在索引为2的位置插入一个新节点,需要将索引为1节点的指针域指向新节点,新节点的指针域指向原索引2的节点,节点插入成功后,插入位置之后的节点索引都会顺序加1,链表的节点数量也会加1。
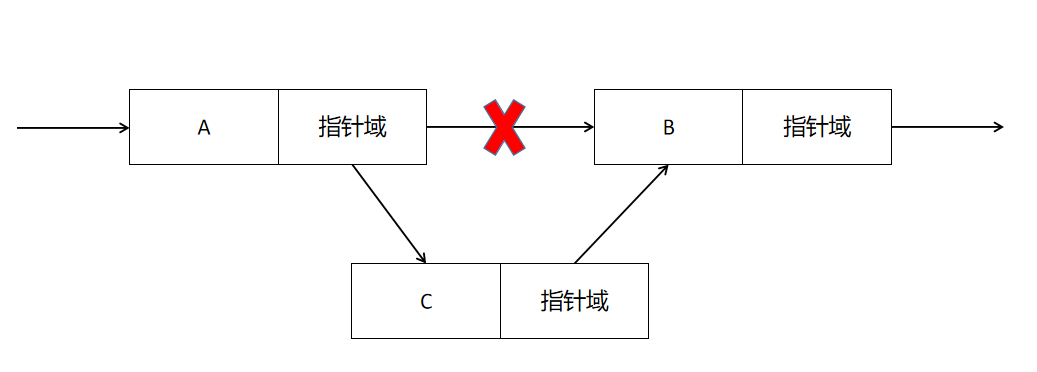
C语言实现链表节点的插入
void insert(Node* pHead,int index,BOOKINFO* pBookInfo)
{
Node *p = pHead->pnode;
Node *pNewNode,*pPreNode;
int i = 0;
while( NULL != p && i < index )
{
pPreNode = p;
p = p->pnode;
i++;
}
if( NULL == p )
{
printf("没有查询到索引为%d的节点",index);
return;
}
// 申请一个新节点
pNewNode = (Node*)malloc(sizeof(Node));
pNewNode->data = (void*)pBookInfo;
pNewNode->pnode = p;
pPreNode->pnode = pNewNode;
}
参数pHead为链表HEAD节点指针,index为新节点插入的索引位置,pBookInfo为书目结构指针。函数将HEAD节点的指针域赋值给指针变量p,使用while循环查询索引位置为index的节点,循环条件是p不为空且变量i小于index,在循环过程中,将p的指针域赋值给p,并将p赋值给指针变量pPreNode,作为当前节点的前驱节点(前一个节点)。
循环结束后,若p为空值,则链表内没有索引位置为index的节点,函数返回。否则申请一个新的节点pNewNode,将pBookInfo赋值给新节点的数据域,p赋值给新节点的指针域,pNewNode赋值给pPreNode,新节点成功插入到链表内。
该运算在长度为n的链表中插入一个节点,插入前链表的长度为n,插入后链表的长度为n+1,index为插入节点的位置。虽然在链表内插入新的节点,不需要节点在内存中移动,只需要修改相应节点的指针域即可,但算法需要遍历链表找到index的插入位置,因此算法的时间复杂度为O(n)。
访问运算
在链表结构中,要访问index位置的元素,需要从链表的头结点开始,依次遍历链表中的每个元素,直至找到index位置的元素,因此链表访问运算的时间复杂度为O(n),其中n为链表的长度。
C语言实现
Node* query(Node* pHead,int index)
{
Node *p = pHead->pnode;
int i = 0;
while( NULL != p )
{
if( i == index )
break;
p = p->pnode;
i++;
}
return p;
}
query()函数从链表的头结点开始,通过循环遍历链表中的每个节点,当节点序号与index相等时,该节点就是要查找的元素。
删除运算
从链表中删除一个节点,需要将被删节点的前驱节点的指针域指向下一个节点,并释放被删节点占用的内存。若被删节点为链表的第一个节点,需要将HEAD节点的指针域指向链表的第二个节点;若被删节点为链表的最后一个节点,需要将链表前驱节点的指针域置空。
C语言实现
// 删除节点
void deleteNode(Node* pHead, int index) {
Node *p = pHead->pnode;
Node *pre = pHead;
int i = 0;
while( NULL != p )
{
// 删除节点
if( i == index )
{
pre = p->pnode;
free(p);
break;
}
p = p->pnode;
pre = p;
i++;
}
}
函数使用了两个Node*指针,p指针用于遍历链表,pre指针指向当前节点的前驱节点,若当前节点为删除节点,则直接将p->pnode指针赋值给pre指针,并释放当前节点占用的内存空间。